背景
在DQN的原文中,需要将游戏最近4帧的图像作为Q网络的输入。这是因为仅仅凭借1帧的画面无法判断物体运动速度和方向等的相关信息。但是在某些情况下,4帧的画面仍然不足以描述完整的状态。面对这种非完全信息的部分可观察马尔可夫过程(POMDP),我们可以使用DRQN来辅助记忆4帧以前的游戏信息。(根据知乎文章1的说法,引入类RNN的层会给模型加入隐藏状态,因此会使MDP退化成POMDP)
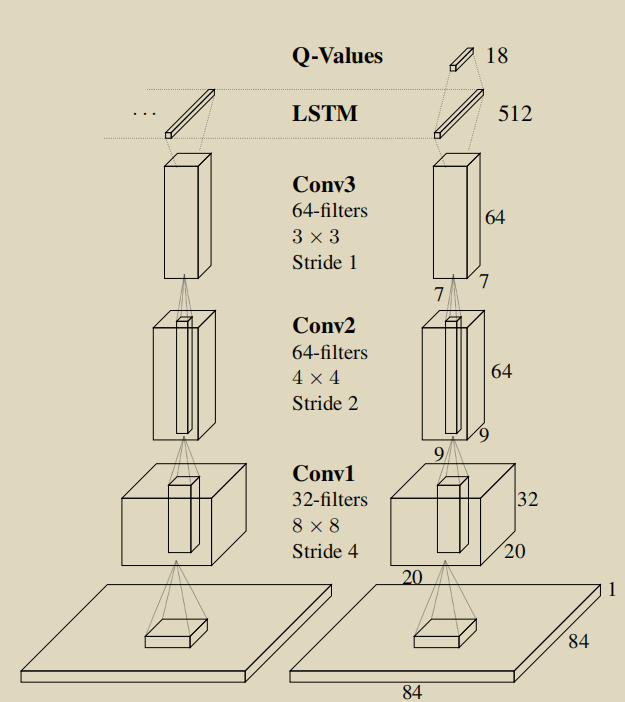
结构
DRQN的结构很简单,只是在DQN的基础上,在全连接层与最后一层卷积层的中间加入LSTM单元。
采样方式
DRQN中的采样方式有两种,分别为Bootstrapped Sequential Update以及Bootstrapped Random Update。Bootstrapped Sequential Update是从episode_memory中随机选取一次游戏过程,并从这次游戏过程的开始一直学习到游戏结束。在每一个时刻,LSTM的隐藏层的状态值从上一个时刻继承而来。
Bootstrapped Random Update从episode_memory中随机选取一次游戏过程,再在这个过程中随机选取一个时刻点,从这个时刻点开始进行若干固定步数的学习。使用这种方式需要在每次切换episode的时候将LSTM隐藏层的状态归零。
Bootstrapped Sequential Update的方式更适合LSTM网络的学习,但其采样方式违背了DQN中采样数据独立同分布的前提条件;Bootstrapped Random Update符合DQN中随机采样的策略,但是其每次切换episode需要将LSTM的状态归零,而这可能损害LSTM层的记忆能力。