回归分析简介
回归分析(Regression)是一种应用极为广泛的统计分析方法,成功应用在金融,经济,管理等领域。它用于分析事物之间的统计关系,侧重考察变量之间的变化规律,并通过回归模型形式描述和反映这种关系。
线性回归分析Linear Regression 是研究一个因变量和一个或多个自变量之间是否存在某种线性关系的统计学方法。若自变量的个数为1,则为一元线性回归分析。若为n(n>1)为多元回归分析。
回归分析与相关分析具有相似之处,其不同在于相关分析主要反映变量间线性关系的密切程度,而回归分析主要反映自变量取值大小对因变量的取值的影响程度。
一元回归分析的数学模型
假设收集到\(n\)对数据\(x_i,y_i(i=1,2,...,n)\),\(x_i\)认为是来自于随机变量\(X\)的一组样本值,\(y_i\)认为是来自于\(Y\)的一组样本统计值。回归分析探讨\(Y\)和\(X\)在统计意义下的相互关系。其中\(X\)和\(Y\)分别被称为自变量和因变量。
一元回归分析的数学模型为:
\[ y=a + bx + \varepsilon \]
其中\(a\)为回归常数,\(b\)为回归系数,\(\varepsilon\)为随机误差。\(y\)的变化由两部分解释:
\(x\)的变化引起\(y\)的线性变化部分,即\(y = a + bx\)
其他随机因素引起的y的变化部分\(\varepsilon\)
回归模型的建立要满足随机误差的数学期望为0,且随机误差的方差为一个特定常数。即有\(E ( \varepsilon ) = 0 , \operatorname { var } ( \varepsilon ) = \delta ^ { 2 }\)。如果对回归模型求期望值,则有\(E(y) = a + bx\)。
一元线性回归模型的建立通常使用最最小二乘法。该方法的基本思路为:根据从总体中随机抽出的一个样本,在平面直角坐标系中找到一条直线,使得观测值\(y_i\)与拟合值\(\hat y_i\)之间的距离最短,即两这之间的残差的平方和最小。公式可表示为:
\[ D = \sum _ { i = 1 } ^ { n } e _ { i } ^ { 2 } = \sum _ { i = 1 } ^ { n } \left( y _ { i } - \hat { y } _ { i } \right) ^ { 2 } = \sum _ { i = 1 } ^ { n } \left( y _ { i } - a - bx _ { i } \right) ^ { 2 } \]
要使上述式子取得最小,可以分别对\(a,b\)求导,得到:
\[ \begin{array} { l } \frac { \partial D } { \partial a } = - 2 \sum _ { i = 1 } ^ { n } \left( y _ { i } - a - b x _ { i } \right) = 0 \\ \frac { \partial D } { \partial b } = - 2 \sum _ { i = 1 } ^ { n } x _ { i } \left( y _ { i } -a - bx _ { i } \right) = 0 \end{array} \]
因此可以解得:
\[ \begin{array} { c } a = \frac { \sum x _ { i } ^ { 2 } \sum y _ { i } - \sum x _ { i } \sum x _ { i } y _ { i } } { n \sum x _ { i } ^ { 2 } - \left( \sum x _ { i } \right) ^ { 2 } } \\ b = \frac { n \sum x _ { i } y _ { i } - \sum x _ { i } \sum y _ { i } } { n \sum x _ { i } ^ { 2 } - \left( \sum x _ { i } \right) ^ { 2 } } = \frac { \sum \left( x _ { i } - \bar { x } \right) \left( y _ { i } - \bar { y } \right) } { \sum \left( x _ { i } - \bar { x } \right) ^ { 2 } } \end{array} \]
可以看出,回归斜率系数的估计值实际上等于自变量和因变量之间的样本协方差与自变量的样本方差之比。
回归方程的统计检验
我们利用最小二乘法获得回归系数及相应的回归方程。至于\(x\)和\(y\)之间是否真有如回归模型所描述的关系,或者说采用所得的回归模型去拟合实际数据是否有足够好的近似。还需得到进一步的判明。
我们需要对回归模型描述实际数据的近似程度,即对所得的回归模型的可信程度进行检验。包括回归方程的拟合优度检验,回归方程的显著性检验,回归系数的显著性检验以及残差分析等。
回归方程的拟合优度检验
拟合优度检验样本数据点聚集在回归线周围的密集程度。从而评价回归方程对样本数据的代表程度。其中统计量为\(R^2\)统计量,称为判定系数:
\[ R ^ { 2 } = \frac { \sum _ { i = 1 } ^ { n } \left( \widehat { y _ { i } } - \bar { y } \right) ^ { 2 } } { \sum _ { i = 1 } ^ { n } \left( y _ { i } - \bar { y } \right) ^ { 2 } } = 1 - \frac { \sum _ { i = 1 } ^ { n } \left( y _ { i } - \widehat { y } \right) ^ { 2 } } { \sum _ { i = 1 } ^ { n } \left( y _ { i } - \bar { y } \right) ^ { 2 } } \]
如果采用单因素方差分析中的解释,即回归方程中总变差为\(SST=SSA+SSE\),则有\(R^2=SSA/SST\)。其反映的是回归方程所能解释的变差的比例。
对于一元线性方程,\(R^2\)也是\(y\)与\(x\)简单相关系数\(R\)的平方:
\[ R = \frac { \sum _ { i = 1 } ^ { n } \left( x _ { i } - \bar { x } \right) \left( y _ { i } - \bar { y } \right) } { \sqrt { \sum _ { i = 1 } ^ { n } \left( x _ { i } - \bar { x } \right) ^ { 2 } \sum _ { i = 1 } ^ { n } \left( y _ { i } - \bar { y } \right) ^ { 2 } } } \]
\(R^2\)的取值范围为0到1,其值约接近于1,则表明模型的解释性越强,在一元线性方程中也表示自变量与因变量的线性关系越强。
回归方程整体显著性检验
其检验因变量\(Y\)与自变量\(X\)之间的线性关系是否显著,用线性模型来描述它们之间的关系是否恰当,即进行整体回归效果的检验。回归方程的显著性检验采用方差分析的方法。对于\(SST=SSA+SSE\)的方差分析形式,研究\(y\)的\(SST\)中模型可解释部分\(SSA\)相对于随机误差部分\(SSE\)是否占较大的比例。
整体回归效果检验采用\(F\)统计量:
\[ F = \frac { S S A } { S S E } = \frac { \sum _ { i = 1 } ^ { n } \left( \hat { y } _ { i } - \bar { y } \right) ^ { 2 } } { \sum _ { i = 1 } ^ { n } \left( y _ { i } - \hat { y } _ { i } \right) ^ { 2 } / ( n - 2 ) } \]
统计量\(F\)的值越大越好,当计算出的值\(F > F_\alpha(1, n-2)\)时,就表明在\(\alpha\)水平上,已解释方差明显大于未解释方差。
回归系数的显著性检验
主要目的是研究回归方程中的每个自变量与因变量之间是否存在显著地线性关系,即研究自变量能否有效地解释因的线性变化,他们能否保留在线性回归模型中。
一元线性回归使用T检验来验证回归系数的显著性。其原假设为回归系数\(b=0\)。统计量为:
\[ \mathrm { T } = \frac { \mathrm { b } } { \frac { \hat { \sigma } } { \sqrt { \sum _ { \mathrm { i } = 1 } ^ { \mathrm { n } } \left( \mathrm { x } _ { \mathrm { i } } - \overline { \mathrm { x } } \right) ^ { 2 } } } } \]
其中有:
\[ \hat { \sigma } ^ { 2 } = \frac { 1 } { n - 2 } \sum _ { i = 1 } ^ { n } \left( y _ { i } - \hat { y } _ { i } \right) ^ { 2 } \]
该统计量服从n-2个自由度的t分布。
对回归系数t统计量的显著性检验,决定了相应的变量能否作为解释变量进入回归方程。当b=0假设成立,意味着x的变化不会引起y的线性变化,x无法解释y,它们之间不存在线性关系, x不能进入回归模型。在一元线性回归分析中,回归方程显著性检验和回归系数显著性检验的作用是相同的,两者可以相互替代。注意,当检验结果没能拒绝原假设时,我们也不能得出自变量与因变量没有关系的结论。因为X与Y之间还可能存在曲线关系。
SPSS中的线性回归分析
通常来说,需要先使用图形-图标构建程序画出散点图与拟合直线,从而大致判断因变量与自变量之间是否存在明显的线性关系。添加拟合线的方法在协方差分析中有提及。例子如下图:
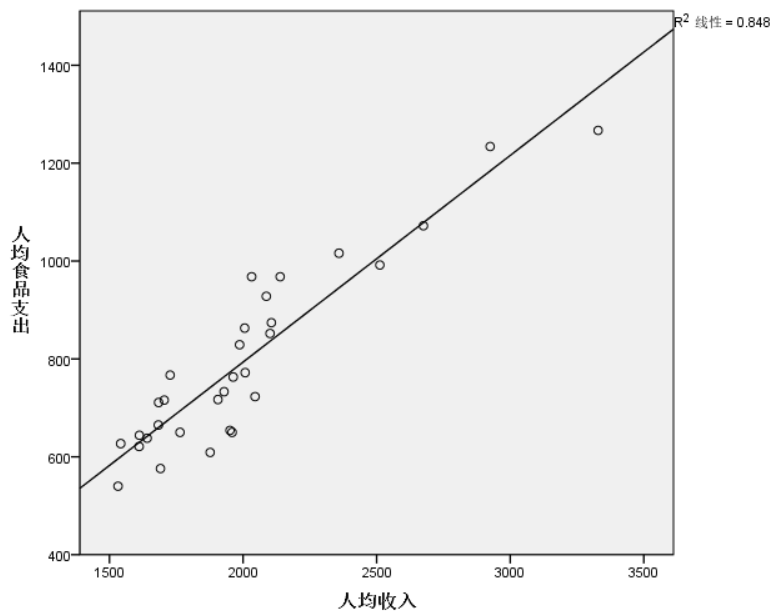
对于根据散点图做出的初步判断,可以使用分析-相关-双变量来验证线性相关性。例子如下图:
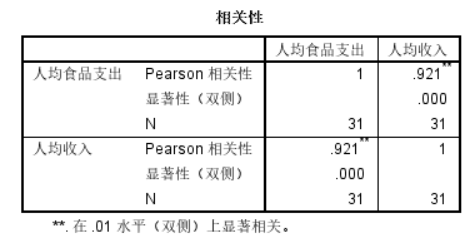
在确定自变量与因变量存在线性相关关系后,可以使用分析-回归-线性来建立线性回归模型。分别将因变量与自变量加入对应框中,并在统计量选框中勾选置信区间选项。分析会生成三个表格。
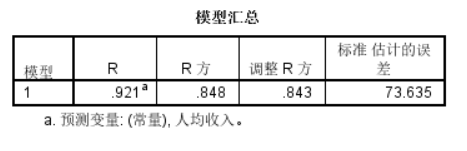
这个表格给出了模型的\(R^2\)值,反映了模型的拟合优度。通常我们使用调整R方作为判断依据。
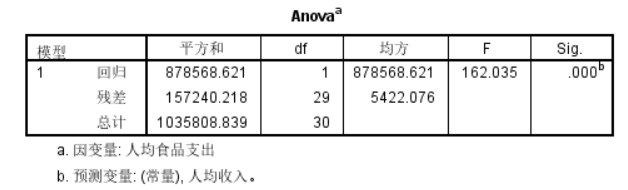
这个表格进行了单因素方差分析,其可以判断回归模型可解释的变差相对于总变差来说是否显著。这部分对应的是回归方程的显著性检验。
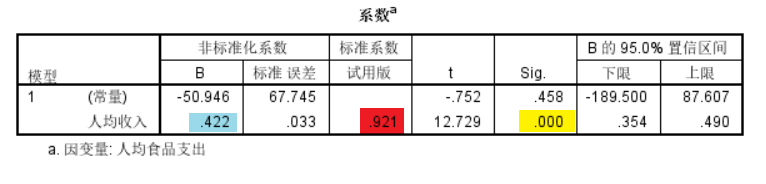
这个表格给出了各个自变量的回归系数以及对应的显著性。回归系数的预测值在蓝色部分,回归系数显著性检验的Sig在黄色部分。由于原假设为回归系数为0,因此当Sig值小于0.05时,则可以认为当前自变量与因变量存在显著线性关系。红色部分时标准化的回归系数(如图,表示人均收入增长1个单位则人均食品支出增长0.921个单位)。